A novel method for short text clustering by using word2vec and cosine similarity
26 Dec, 2019Short text clustering
Text clustering is to transform the individual document from the original natural language text into mathematical information, which is presented in the form of high-dimensional space points.
Clustering of long texts is easier because they contain a larger amount of words and more features per text, which helps clustering.
However, for short texts, especially in the form of tweets, each sample has fewer features. If the idea in the vector space model is used, the feature vector constructed by each sample will be very sparse. Eventually, the clustering of short texts simply becomes a short text aggregation at the level of "word repetition".
Word2vec and cosine similarity
Natural language is a complex system used to express meaning. In this system, words are the basic unit of meaning. As the name implies, a word vector is a vector used to represent a word, and can also be considered as a feature vector or representation of a word. The technique of mapping words to vectors is also called word embedding.
We can use one-hot vector to represent words. Suppose the number of different words in the dictionary (the dictionary size) is N, and the index of a word is i. To get the one-hot vector representation, we create a vector of length N with all 0s and set its ith bit to 1.
Although the one-hot word vector is easy to construct, it is usually not a good choice. One of the main reasons is that the one-hot word vector does not accurately represent the similarity between different words, such as the cosine similarity we often use.
Cosine similarity is a measure of similarity between two non-zero vectors of an inner product space that measures the cosine of the angle between them. The cosine of 0° is 1, and it is less than 1 for any angle in the interval (0,π] radians. It is thus a judgment of orientation and not magnitude: two vectors with the same orientation have a cosine similarity of 1, two vectors oriented at 90° relative to each other have a similarity of 0, and two vectors diametrically opposed have a similarity of -1, independent of their magnitude. [wiki]
The word2vec tool is used to solve the above problem. It expresses each word as a fixed-length vector and makes these vectors better express the similarity and analogy between different words.
Database
In late 2017, a Clemson University research group began to catalogue Twitter activity from specific accounts. This set included nearly three million Tweets associated with 2848 unique Twitter handles, categorized by the type of content each account focused on. Data was obtained from Kaggle.
First, the tweets have been ‘cleaned’ for the convenience of the next steps. We then use gensim library in python and this dataset to generate our word2vec model.
Clustering
For clustering, we choose the 10,000 most common words from our model and initialize each word with a value of zero. We then project our tweets onto this 10,000x1 vector by using similarity as calculated by our word2vec model [1].
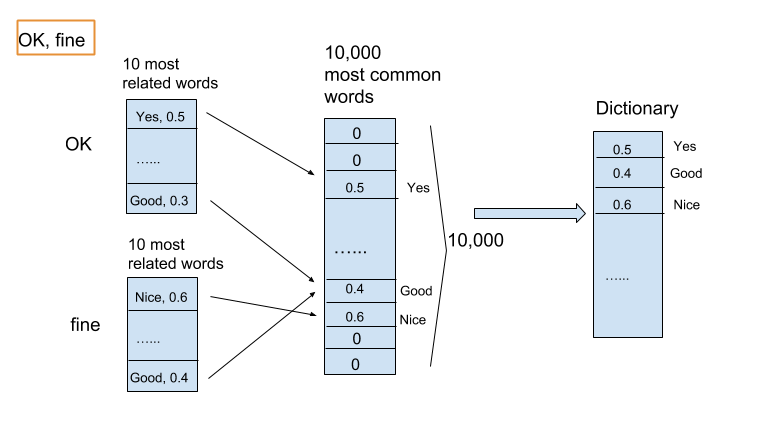
For example, for the words ‘OK’ and ’fine’, we choose the 10 most similar words from our model to represent it. Next, if these 10 words can all be found in the set of 10,000 common words, we replace the 0 value of each word with that similarity value; if the value is already non-zero, the larger similarity value is kept. As a result, we are able to transform each tweet into a 10,000x1 sparse vector.
After obtaining these vectors, the cosine similarity was used to compare the closeness between Tweets.
Hierarchical clustering, also known as hierarchical cluster analysis, is an algorithm that groups similar objects into groups called clusters. The endpoint is a set of clusters, where each cluster is distinct from each other cluster, and the objects within each cluster are broadly similar to each other.
Here, because of the complexity, we’ll use a method similar to hierarchical clustering. For example, we assign a group to the first tweet, then compare the cosine similarity with the rest of the tweets’ vectors. If the cosine similarity is larger than the threshold, we’ll group those Tweets. Then the rest of the tweets’ vectors have to compare the cosine similarity with this group and get an average value to compare to the threshold. However, to simplify the computation, we only compare to the maximum of the first 5 tweets’ vectors in the group for the rest of tweets’ vectors.
We then use TF-IDF to extract 10 key words as an topic indicator for the group if the group contains more than 20 tweets’ vectors. From these 10 key words, we can characterize the topic of this group.
Results
We clustered a subset of 35,804 from our total tweet set during 6/2017. The threshold for cosine similarity was set to 0.3. From the 10 key words obtained through TF-IDF, we can assess the topic of that group. Here is one group of key words we get:
['uk', 'elect', 'may', 'prime', 'minist', 'gambl', 'parliament', 'backfir', 'politician', 'result']
Put these words in google, we can easily get the topic we search for:
Further discussion
We tried euclidean distance as well to compare with cosine similarity. The first tweet we chose is:
“hi rememb prais harvey weinstein wonder human good friend powerhous disavow”
Here is some result we get in the order of index:
| Euclidean distance | Cosine similarity |
|---|---|
| 11 - “hi rememb said weinstein wonder human good friend pow- erhous disavow” | 11 - “hi rememb said weinstein wonder human good friend pow- erhous disavow” |
| - | 223 - “happi thanksgiv good day famili” |
| - | 357 - “5 day silenc hillari succumb pressur condemn friend wein- stein” |
| - | 388 - “obama final speak accus rapist friend harvey weinstein” |
| 515 - “maxin water declar hous human right” | - |
| 605 - “boom jr ruin woodi allen defend harvey weinstein” | 605 - “boom jr ruin woodi allen defend harvey weinstein” |
| 702 - “ha donna karan regret defend harvey weinstein” | 702 - “ha donna karan regret defend harvey weinstein” |
| ...... | ...... |
| - | 1377 - lena dunham defend writer accus rape well im realli surpris lena dunham hillari clinton good friend |
| ...... | ...... |
It is obvious that cosine similarity is more accurate and functional.